Get Started with xLearn !¶
xLearn is a high-performance, easy-to-use, and scalable machine learning package, which can be used to solve large-scale machine learning problems, especially for the problems on large-scale sparse data, which is very common in scenes like CTR prediction and recommender system. In that case, if you are the user of liblinear, libfm, or libffm, now xLearn is your another better choice. This is because xLearn handles all the models and features in these platforms using an uniform way, and it provides better performance, ease-of-use, and scalability.
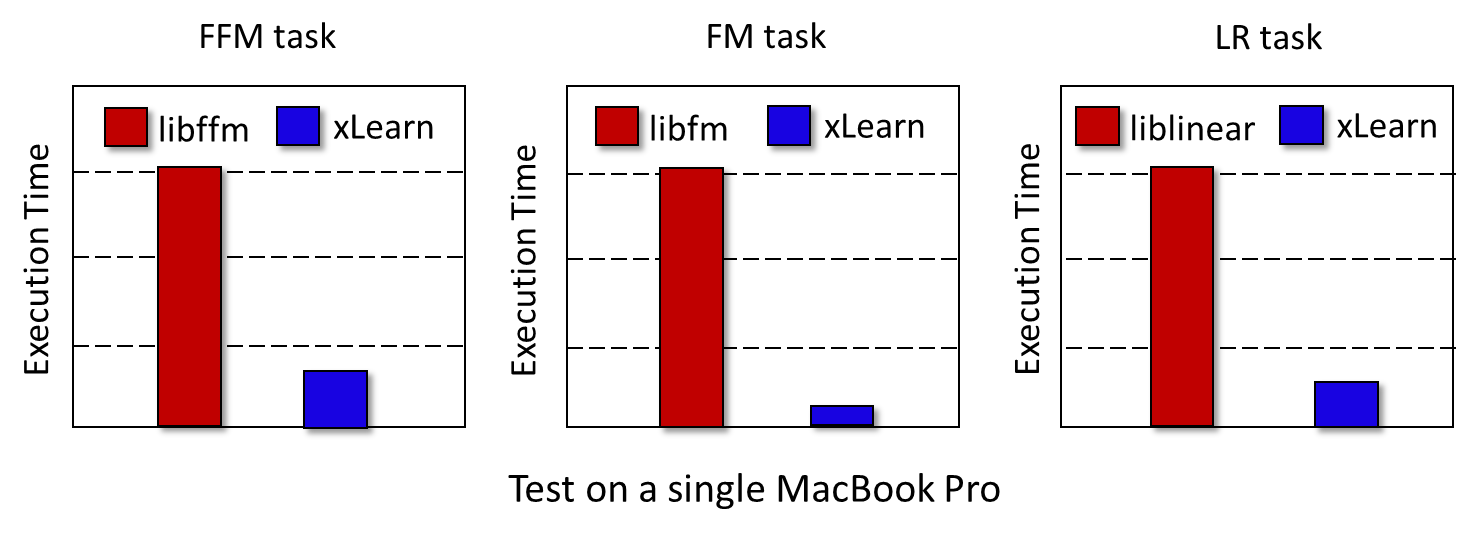
A Quick Example¶
This is a quick start tutorial showing snippets for you to quickly try out xLearn on a small demo dataset (Criteo CTR prediction) for a binary classification task. In this example, the machine learning algorithm will predict that if current user will click a specified online advertisment.
Installation¶
The easiest way to install xLearn Python package is to use pip. The following command will
download the xLearn source code, build and install python package on your locally machine:
sudo pip install xlearn
The installation process will take a while to complete, please wait with patience. After the installation, users can use the following script in Python script to check whether the xLearn has been installed successfully:
>>> import xlearn as xl
>>> xl.hello()
You will see the following message if you installed xLearn successfully:
-------------------------------------------------------------------------
_
| |
__ _| | ___ __ _ _ __ _ __
\ \/ / | / _ \/ _` | '__| '_ \
> <| |___| __/ (_| | | | | | |
/_/\_\_____/\___|\__,_|_| |_| |_|
xLearn -- 0.44 Version --
-------------------------------------------------------------------------
If you meet any installation problem, or you want to build the latest code from Github, or you want to use the xLearn command line API instead of the Python API, you can see how to build xLearn from source code in Installation Guide.
Python Demo¶
Here is a simple Python demo no how to use FFM algorithm of xLearn for solving a binary classification problem:
import xlearn as xl
# Training task
ffm_model = xl.create_ffm() # Use field-aware factorization machine (ffm)
ffm_model.setTrain("./small_train.txt") # Set the path of training dataset
ffm_model.setValidate("./small_test.txt") # Set the path of validation dataset
# Parameters:
# 0. task: binary classification
# 1. learning rate: 0.2
# 2. regular lambda: 0.002
# 3. evaluation metric: accuracy
param = {'task':'binary', 'lr':0.2, 'lambda':0.002, 'metric':'acc'}
# Start to train
# The trained model will be stored in model.out
ffm_model.fit(param, './model.out')
# Prediction task
ffm_model.setTest("./small_test.txt") # Set the path of test dataset
ffm_model.setSigmoid() # Convert output to 0-1
# Start to predict
# The output result will be stored in output.txt
ffm_model.predict("./model.out", "./output.txt")
This example shows how to use field-aware factorization machines (FFM) to solve a simple binary classification task. You can check out the demo data
(small_train.txt and small_test.txt) from the path demo/classification/criteo_ctr.