Large-Scale Machine Learning¶
This page shows how to use xLearn to solve large-scale machine learning problems. In recent years, challenges arise with the fast-growing data. For “big-data”, we focus on datasets with potentially trillions of training examples, which cannot fit into the memory of a single machine. Motivated by this, we design xLearn to solve large-scale machine learning problems. First, xLearn can handle very large data (TB) on a single PC by using out-of-core learning. In addition, xLearn can scale beyond billions of example across many machines to support distributed training by using the parameter server framework.
Out-of-Core Learning¶
Out-of-core leanring refers to the machine learning algorithms working with data cannot fit into the memory of a single machine, but that can easily fit into some data storage such as local hard disk or web repository. Your available RAM, the core memory on your single machine, may indeed range from a few gigabytes (sometimes 2 GB, more commonly 4 GB, but we assume that you have 2 GB at maximum) up to 256 GB on large server machines. Large servers are like the ones you can get on cloud computing services such as Amazon Elastic Compute Cloud (EC2), whereas your storage capabilities can easily exceed terabytes of capacity using just an external drive (most likely about 1 TB but it can reach up to 4 TB).
Actually, the ability to learn incrementally from a mini-batch of instances is key to out-of-core learning as it gurantees that at any given time there will be only a small amount of data in the main memory. Choose a good size for the mini-batch that balances relevancy and memory footprint could involve some tuning.
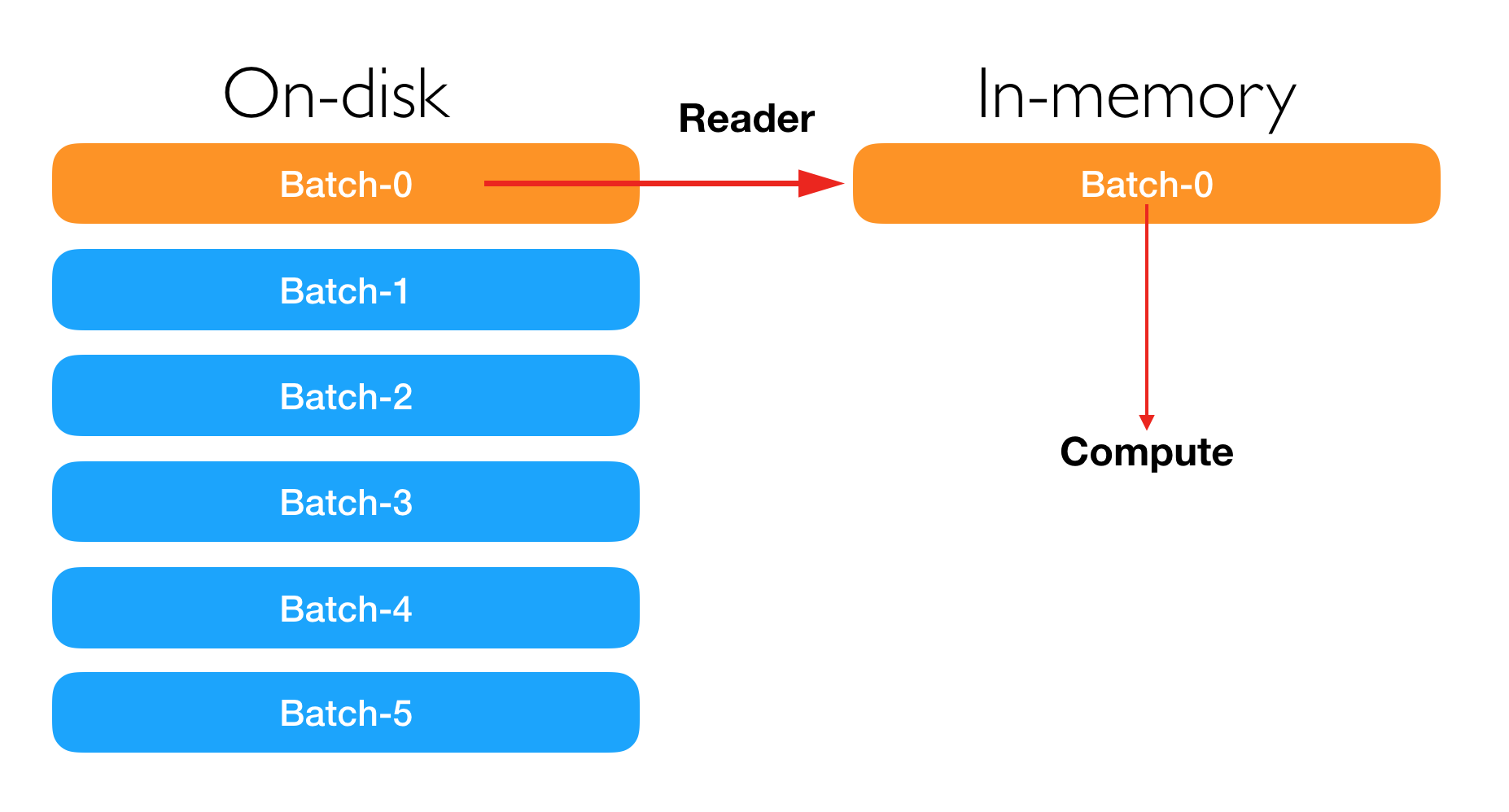
Out-of-Core Learning Using xLearn Command Line¶
Is’s very easy to perform out-of-core learning in xLearn command line, where users can just use the --disk
option, and xLearn will help you do all the other things. For example:
./xlearn_train ./big_data.txt -s 2 --disk
Epoch Train log_loss Time cost (sec)
1 0.483997 4.41
2 0.466553 4.56
3 0.458234 4.88
4 0.451463 4.77
5 0.445169 4.79
6 0.438834 4.71
7 0.432173 4.84
8 0.424904 4.91
9 0.416855 5.03
10 0.407846 4.53
In this example, xLearn can finish the training of each epoch in nearly 4.5 second.
If you delete the --disk option, xLearn can train faster.
./xlearn_train ./big_data.txt -s 2
Epoch Train log_loss Time cost (sec)
1 0.484022 1.65
2 0.466452 1.64
3 0.458112 1.64
4 0.451371 1.76
5 0.445040 1.83
6 0.438680 1.92
7 0.432007 1.99
8 0.424695 1.95
9 0.416579 1.96
10 0.407518 2.11
In this time, the training of each epoch will only spend nearly 1.8 seconds.
We can set the block size for on-disk training by using -block option. For example:
./xlearn_train ./big_data.txt -s 2 -block 1000 --disk
In this example, we set the block size to 1000MB. On default, this value will be set to 500.
Users can also use --disk option in the prediction task:
./xlearn_predict ./big_data_test.txt ./big_data.txt.model --disk
Out-of-Core Learning Using xLearn Python API¶
In Python, users can use setOnDisk API to perform out-of-core learning. For example:
import xlearn as xl
# Training task
ffm_model = xl.create_ffm() # Use field-aware factorization machine
# On-disk training
ffm_model.setOnDisk()
ffm_model.setTrain("./small_train.txt") # Training data
ffm_model.setValidate("./small_test.txt") # Validation data
# param:
# 0. binary classification
# 1. learning rate: 0.2
# 2. regular lambda: 0.002
# 3. evaluation metric: accuracy
param = {'task':'binary', 'lr':0.2,
'lambda':0.002, 'metric':'acc'}
# Start to train
# The trained model will be stored in model.out
ffm_model.fit(param, './model.out')
# Prediction task
ffm_model.setTest("./small_test.txt") # Test data
ffm_model.setSigmoid() # Convert output to 0-1
# Start to predict
# The output result will be stored in output.txt
ffm_model.predict("./model.out", "./output.txt")
We can set the block size for on-disk training by using block_size parameter.
Out-of-Core Learning Using xLearn R API¶
The R guide is coming soon.
Distributed Learning¶
As we mentioned before, for some large-scale machine challenges like computational advertising, we focus on the problem with potentially trillions of training examples and billions of model parameters, both of which cannot fit into the memory of a single machine, which brings the scalability challenge for users and system designer. For this challenge, parallelizing the training process across machines has become a prerequisite.
The Parameter Server (PS) framework has emerged as an efficient approach to solve the “big model” machine learning challenge recently. Under this framework, both the training data and workloads are spread across worker nodes, while the server nodes maintain the globally shared model pa- rameters. The following figure demonstrates the architecture of the PS framework.
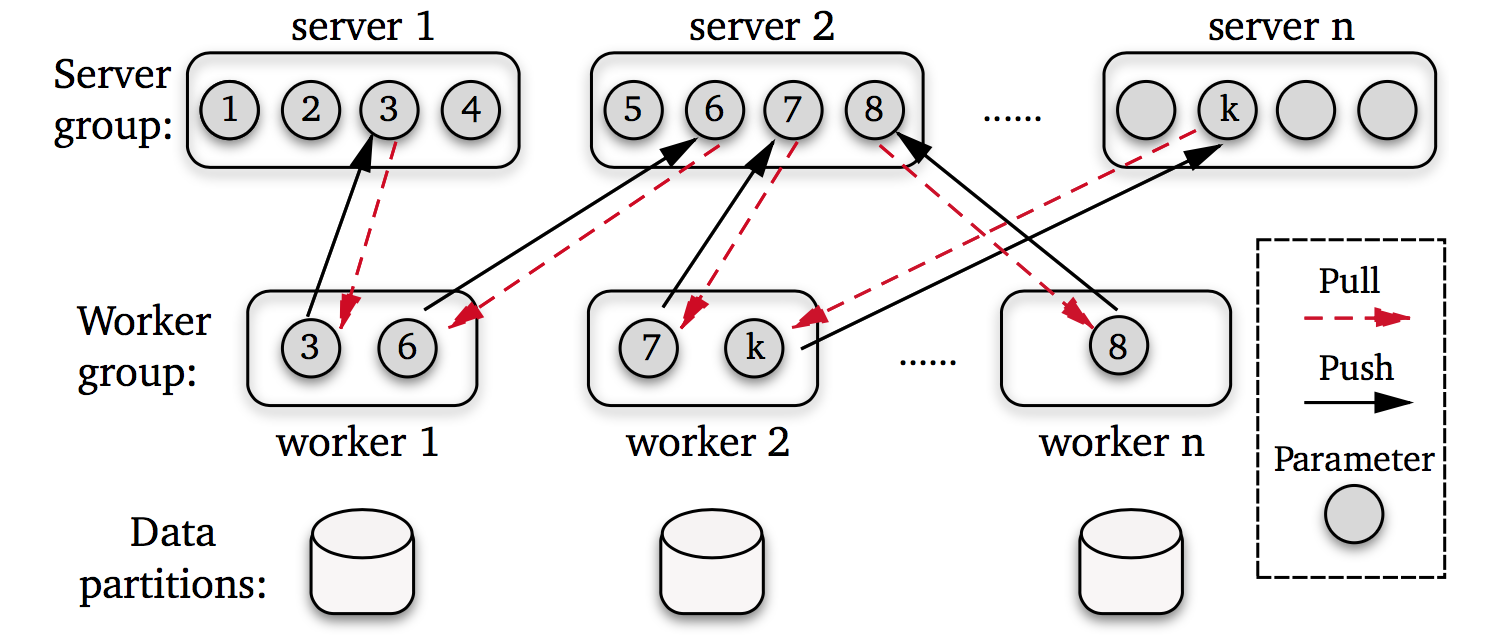
As we can see, the Parameter Server provides two concise APIs for users.
Push sends a vector of (key, value) paris to the server nodes. To be more specific – in the distributed gradient descent, the worker nodes might send the locally computed gradients to servers. Due to the data sparsity, only a part the gradients is non-zero. Often it is desirable to present the gradient as a list of (key, value) pairs, where the feature index is the key and the according gradient item is value.
Pull requests the values associated with a list of keys, which will get the newest parameters from the server nodes. This is particularly useful whenever the main memory of a single worker cannot hold a full model. Instead, workers prefetch the model entries relevant for solving the model only when needed.
The distributed training guide for xLearn is coming soon.